A quick little update of something we've added for amateur sondehub users - web based decoders for horus and wenet.
webhorus can demodulate horus binary 4fsk and upload to sondehub using either input from a sound card (most browsers) connected to an SSB radio or from an RTL-SDR (Chrome only). Mark's made a demo video of this working in action off a mobile phone!
webwenet can demodulate and upload to ssdv and sondehub using RTL-SDR (Chrome only). Like it also works (barely) on a mobile phone!
Both can be installed as Progressive Web Apps, so they can look and feel like a real app, along with work offline. In Safari use the share icon to add to dock or home screen. In Chrome you'll find an "Install webhorus" or add to home screen button depending on mobile or desktop.



URLS: https://horus.sondehub.org and https://wenet.sondehub.org
GitHub: https://github.com/projecthorus/webhorus
Technical write up : https://sprocketfox.io/xssfox/2025/03/07/webhorus/
2025-03-29 23:01:25 +0000 UTC
View Post
Hi all!
Apologies for the long time between updates here - we really appreciate your continuing support!
Once again we are very happy to announce that GRAW Radiosondes are continuing their support of SondeHub. Their generous support allows us to keep SondeHub running and available to everyone. Without their support it would be much harder to provide the services and features we do.

You can find out more about GRAW Radiosondes on their website.
SondeHub Tracker Updates
Lots of work has gone into improving the performance of the SondeHub Tracker, and resolving many outstanding issues. These updates include:
Improvements to initial page load by fetching data while the splash screen loads
Changes to the colours used, to better increase contrast and ease confusion
Rendering fixes
Performance and usability improvements - focusing around mobile users
Many many bug fixes
We’re working on bringing these updates across to the SondeHub-Amateur tracker (which is a separate codebase).
radiosonde_auto_rx v1.8.0
One of the big updates in the past few months has been the release of radiosonde_auto_rx v1.8.0. This release includes full support for the open-source KA9Q-Radio network SDR server, which allows us to monitor the entire 400-406 MHz radiosonde band using an Airspy R2 or Mini and a RPi 4 or better. We’ve already seen reports of stations decoding 10 radiosondes simultaneously!
This has been a long time coming, and I’d like to give a big thanks to Clayton Smith and Andrew Koenig for doing a lot of the work on this one. Also a big thanks to Phil Karn KA9Q for providing the community with such awesome software!
If you’re in an area where you regularly see more than a few radiosondes simultaneously, we highly recommend that you look into upgrading to an Airspy+KA9Q based receiver setup.
Screenshot: An example of rasiosonde_auto_rx decoding ~10 radiosonde simultaneously - Thanks to DJ2DS for this!

2025-01-05 00:02:54 +0000 UTC
View Post
Hi all,
We are starting to see misidentifications of DFM-17 sondes as DFM-09 sondes becoming more prevalent over the US.
We're working through a few options for how to better handle mis-identification of DFM17 sondes (based on serial number amongst a few other things), but this will take time to implement, and will probably need software updates at a majority of stations to work.
For now, if you see a 'DFM09' with a serial number starting with 23 or 24 then it's most likely actually a DFM17 (very likely for 24).
73
Mark VK5QI
For updates around the issue check out the sondehub-infra github issue.
2024-05-18 06:09:49 +0000 UTC
View Post
Discord
After having development discussions spread across multiple Discord servers for many years, we’ve decided to finally setup our own Discord server in an attempt to centralise things. We have channels for software development, and also general radiosonde hunting and amateur balloon launching discussion!
If you’ve previously linked your Patreon and Discord accounts ( https://www.patreon.com/posts/how-to-link-your-96158411 ) then you will have already been added to our server. If not, you can join with this invite link: https://discord.gg/9PQuq5jUGR
SondeHub Logo
If you’re been looking at the SondeHub or SondeHub-Amateur tracker recently, you might have noticed a change in the logo! Our logo originally comes from the HabHub project, and was designed by members of Cambridge University SpaceFlight (CUSF), and we thank them for making such a cool balloon logo! Since the main developers of SondeHub live in Australia, we decided to ‘localise’ the logo a little, keeping the style but ‘spinning the globe’ over to our part of the world. You’ll find both the old and new logos continue to be used throughout the SondeHub websites.
TTN / Helium
We’ve noticed some interest in using LoRaWAN trackers on The Things Network and the Helium Network for tracking high-altitude balloons, in particular floater payloads.
To help make getting telemetry from these payloads into SondeHub-Amateur as easy as possible, we’ve built gateways for both of these networks, which users can configure their TTN/Helium setups to send data to using a HTTP or WebHooks integration.
Documentation on how to use these gateways is still in development, but there’s some initial information available on the sondehub-infra wiki here: https://github.com/projecthorus/sondehub-infra/wiki/Helium-&-TTN-(LoRaWAN)-Gateway
Recovery Report ActivityPub Bot
This bot reports recoveries on ActivityPub and can be subscribed to using Mastodon. Search for @sonderecovery@internaluse.net. It’s fun seeing all the recovery stories every day.
Cool community-developed projects using SondeHub data
We’re now seeing our APIs and data being used in other applications, providing useful tools and visualisations.
Jeremy Elson has developed some nice utilities and visualisations making use of the SondeHub radiosonde database. These include an email notifier system for radiosonde landings, and a heatmap of radiosonde landing locations.
Chris Remboldt has as a website ‘SondeFinder’ which allows searching for recent radiosonde landings in a user-defined area, and can also do some estimation of the landing site for sondes that weren’t tracked down to the ground.
If you have any other projects that you think we should feature on a future post, please let us know!
2024-03-12 23:45:31 +0000 UTC
View Post

I am very happy to announce that GRAW Radiosondes are continuing their support of SondeHub for 2024. We are very appreciative of their support in 2023 which has enabled many new features to be developed on SondeHub. Their generous support allows us to keep SondeHub free to use at the service level our users have come to expect.
We are looking forward to working and collaborating with GRAW Radiosondes again over the next year as there are some exciting opportunities for us to help each other.
You can find out more about GRAW Radiosondes on their website.
2023-12-31 13:01:00 +0000 UTC
View Post
We recently made some changes to how our radiosonde predictions (for SondeHub not SondeHub Amateur) are delivered to clients.
Previously the web client would request predictions for every single radiosonde. On the backend predictions are run on a schedule, so from a server load perspective having the client request all the data didn't create much additional load. However as the number of active radiosondes has grown over time, this has resulted in a larger and larger payload over time. Sometimes reaching 1MB. This is requested from the client every minute. Obviously this quickly adds up in total bandwidth, not to mention this can be annoying for mobile users both from network and memory usage perspective. This polling method also meant that there could be a delay of up to 2 minutes before the latest prediction was shown.
After moving to a culling system for radiosondes we recognised that the next big change we could make to save on bandwidth and improve performance was to also cull predictions. However culling predictions using the API would decrease performance as we wouldn't be able to heavily cache predictions like we did before.
It made sense for us to start delivering predictions via our websockets delivery method. This has some bandwidth benefits which should help reduce our overall AWS spend, but also helps with the polling problem. As predictions are generated they are pushed out to websockets, allowing for clients to see the latest prediction as soon as it's available. We've already had some anecdotal feedback reporting the improvement - which is great news.

We can already see a massive improvement in the amount of data transferred to clients in our backend metrics, along with a reduction in total number of requests. Both of these have a financial impact. Hopefully the web/mobile client experience has also improved however as we don't any tracking systems on the site we don't have any qualitative measurement to confirm this.

That's all for today, happy sonde hunting.
~ Michaela
2023-10-08 04:09:48 +0000 UTC
View Post
APRS receiver positions

Our APRS importer should now import the positions of stations that receive balloon telemetry.
APRS chase car positions

Additionally appending "SHUB" or "SHUB1-1" to APRS paths will result in positions being uploaded to SondeHub as chase car positions.
2023-08-17 09:40:13 +0000 UTC
View Post
In computer game development there is a fairly common optimisation called frustum culling.

In the example above, the players camera is on the right. When the player moves their camera around the game engine stops rendering all the objects outside of the view of the camera. Since the player can't see behind them, there's no point rendering all those extra bits of the game.
So what does this have to do with SondeHub? Well SondeHub tracker is a fork of the HabHub tracker. HabHub was all about tracking amateur balloons. At anyone time there might of been 10 or so balloons on the HabHub tracker. It was feasible for the website to handle rendering all those balloons. SondeHub on the other hand is handling ~200 radiosondes each peak.
We've been delivering and displaying all that data. Every radiosonde telemetry frame has been sent the browser and the browser has tried to plot each and everyone.
What's the impact of this:
- Infrastructure costs: the number of servers required to send all that data
- Data transfer costs: the cost send to that data to you
- Client / browser performance
So what is SondeHub changing?
First off, data ingestion, archiving, and our APIs haven't and won't be changing. If you are using any of our APIs they will continue to work like usual.
We are effectively trying to implement the same style of frustum culling that games do but for SondeHub. We don't want to download and render any of the data that isn't visible on the map.
What we have implemented is in the tracker webpage. When this feature is released the web interface is going to change a little. The first noticeable change is that high zoom levels ( like where you can see most of the world ) you'll notice a little warning on the map.

The data presented when at this zoom level is what we call the slow feed. It'll show the rough location of all the radiosondes in the air right now plus any new ones that are detected. Once you zoom in, the locations of the radiosondes visible on the map will begin to update.

You'll also notice that we no longer display the trails, and predictions by default. Don't worry, they are still there! Click on the radiosonde or selecting from the menu will display the path and predictions like normal.

Hiding the trails/predictions results in a lot less work for the web browser, making the page quicker to use. It is also required as the client might not have the data required due to the culling.
You can get an idea of how many radiosondes your browser is currently tracking by looking at the debugging information in the bottom right hand corner of the map.

With these changes we hope to reduce our hosting bill and improve the client side experience.
Why didn't we do this sooner?
It's actually a fairly difficult problem to solve and we wanted to make sure we solved it in a way that didn't impact usability of our users. We also need to make sure the changes don't just move costs from one part of the platform to the other.
We believe we've struck a good balance between optimisation and usability.
Help wanted!
Before we roll out these changes we want to make sure they work reliably and that our Patreons aren't impacted by any usability concerns. For that we ask that you help test. To do so use our testing site:
https://testing.v2.sondehub.org/
If you find any bugs that impact you please report them to GitHub Issues or otherwise add a comment in this post.
2023-08-14 06:00:59 +0000 UTC
View Post
Summary
If you are using rdz_ttgo_sonde software - upgrade to 20230427 / 0.9.3 or beyond ASAP. Failure to do so may prevent uploads to SondeHub.
Why and how we block old software versions
Blocking uploads from old versions is not something we like doing. We try to avoid it where possible. However in certain cases bugs in decoders and software result in incorrect data being uploaded to SondeHub. This can take the form of:
- Incorrect positions
- Incorrect PTU (pressure temperature humidity) data
- Incorrect serial number generation
- Incorrect type identification
As decoders are based on reverse engineering and written by many people in the community these bugs and decoder quirks are very easy to end up in software and cause inconsistent data to end up in SondeHub. We try our best to reach out to developers to get these fixed up (and thank you to all the developers who work with us!). It's hard to test across the shear number of different radiosonde types so it's easy for mistakes to happen.

Here's an example DFM temperatures being decoded differently between auto-rx and rdz_ttgo_sonde.
When we detect issues with a various version we give some time for developers to debug, fix and release a new version. We then also wait a period of time for users to upgrade. This is why it's important that you try to keep your software up to date!
Next we try to identify if the issue only impacts a certain radiosonde type. If the issue is only with a specific type of radiosonde we limit the version blocking to that type.
Why don't we decode radiosondes on the backend?
We've looked into the possibility of decoding radiosondes in the backend. The idea behind this is that a basic demodulator would decode the bits in a radiosonde frame and then upload it SondeHub to perform the decoding. Doing this would mean consistent decoding of the data. This type of decoding would likely work for some radiosonde types like the RS41 where most of the data is encapsulated in a single frame of data.
However for other radiosonde types it would require keeping state between frames - this would require some amount of time sync to work with multiple stations and processing of messages in order. Something that's a little tricker to arrange at our scale. Maybe one solution might be to upload long overlapping bitstreams.
This becomes a much harder and complex task than the current process. Something we haven't given up on, but it's not something we are actively working on due to the complexity.
rdz_ttgo_sonde 0.9.2
That brings us to rdz_ttgo_sonde 0.9.2. This version of rdz_ttgo_sonde misidentifies DFMs causing the PTU data to be incorrectly calculated. The issue has been fixed since April however a large number of users are still on the old version.
If you are using rdz_ttgo_sonde 0.9.2 please upgrade. If you know of people using rdz_ttgo_sonde 0.9.2 please ask them to upgrade. We will eventually be blocking uploads of DFM radiosondes on 0.9.2. This post has been made public so you may share it with other users.

There are still a large number of users on 0.9.2 and we'd like to see the number drop.
2023-07-12 06:46:36 +0000 UTC
View Post
Back when SondeHub first got off the ground there were only a few tracking stations. We published all data to the web clients as it came in. Today there are 1300+ receiving stations feeding data and many older computers and mobile phones struggle with showing the unfiltered map.
A longer term goal as we scaled up has been to improve the web experience by only receiving and drawing the data that's relevant to the user. Most people only look at a small section of the map and don't require the full feed.
We already have topics in our MQTT that allow the web interface to only show selected radiosondes based on serial number. The idea is that we extend this functionality to only display the radiosondes for the map extent visible by only subscribing to the serial numbers in that area. The tricky part here is finding which serial numbers are for an area. Luckily there's already an API that lists all sondes currently in flight.
That leaves us with one missing piece - what happens if a sonde is only just launched - how does the web client find out about this radiosonde.
As of yesterday we have some new low bandwidth feeds - sondes-new/#. This feed provides an "at least once" broadcast of a radiosonde when its first seen. Due to technical constraints it's not guaranteed that it'll only be sent once - however the throughput is slow enough to solve our above problem.
This paves the way for the future web interface changes to improve usability and performance.
AWS Outage
Just a quick note here that this morning AWS suffered an outage in the us-east-1 region. As we are hosted in this region we were also impacted. Once the AWS outage was cleared SondeHub recovered without human intervention (I was asleep). Most of the radiosonde software currently doesn't retry sending data, as a result there were a few hours of lost data.
2023-06-14 00:50:05 +0000 UTC
View Post
Thanks for Mark (VK5QI) for writing todays patreon post!
ARDC Grant
Back in November 2022 we submitted a grant request to Amateur Radio Digital Communications, for funding for approximately 2 years of hosting costs. We are very happy to announce that our grant request was approved!
https://www.ardc.net/apply/grants/2023-grants/grant-balloon-tracking-platform/
Even with this grant, Patreon pledges are still vital to ensuring that SondeHub has funding for ongoing operation, and we are ever thankful to all of you that continue to show your support!
Sondehub-Amateur Time Period Updates
Up until now, the SondeHub-Amateur tracker has only allowed viewing of up to 3 days of historical data (though older data has been available via our Grafana dashboards).
Recently we added support for up to 7 days of history for unfiltered queries, and up to 1 year history for filtered queries.
This is most useful for tracking pico-balloons that have been in the air for a long time, for example to track the path of the W5KUB-113 flight over the last year, enter ‘W5KUB-113’ in the search box at the top-left of the tracker, press enter, and then you will be able to select the longer time periods from the drop-down box at the top-left of the map:

Unfortunately we have run up against some limitations of the mapping library we are using (Leaflet), in how it handles tracks that cross over +/- 180 degrees Longitude, resulting in tracks being ‘cut’ at this longitude. We have a few ideas on how to fix this, all fairly complicated, but hopefully we will get this resolved eventually.
SondeHub-Amateur APRS-IS Gateway Upgrades
Since SondeHub-Amateur began, we have run an APRS-IS gateway to import positions from amateur balloons that report into the APRS-IS network. This captures all flights which transmit APRS telemetry, and also WSPR flights which have their data submitted to APRS-IS via various gateways.
There are many different approaches to sending telemetry information via APRS packets. While APRS does have a specification for telemetry packets, this seems to be rarely used in high-altitude balloon payloads, with developers preferring to put telemetry data into the APRS comment field, in various formats.
Recently, Mark VK5QI has added support for the comment-field telemetry format for a few of the more popular high-altitude balloon APRS trackers models, and are working on adding support for more.
The currently supported models include the:
- High Altitude Science StratoTrack
- LightAPRS
- WB8ELK SkyTracker
This means that telemetry data from these tracker models will now be shown on amateur.sondehub.org, and be available for plotting on our Grafana instance (easily accessible via the ‘Plots’ button on the tracker).


More information on the telemetry formats supported is available here: https://github.com/projecthorus/sondehub-aprs-gateway#telemetry
2023-04-16 09:47:51 +0000 UTC
View Post
Going to try to be brief (future me here - turns out this update was less brief than I thought it would be - we've been doing a lot!) because everything has been a lot lately but I wanted to cover some of the things we've been working on behind the scenes.
MQTT WebSocket compression issues
For several months we've been running "per-message-deflate" on our WebSockets solution which powers our tracker page and third party access. This has saved us significantly in bandwidth usage. However we've been seeing our WebSocket servers crash with a segfault. Unfortunately when the crash occurs it happens to all our servers at once, so the impact is significant.

We were able to get core dumps, but after help from several people and a lot of GDB debugging we were unable to determine the problem or a suitable solution. The problem could lie within mosquitto, or libwebsockets but we are unable to determine.
Another approach we looked at was using a modified version of python wsproxy project to provide the compression. The problem with this solution is that it used significantly more CPU than was acceptable. At this stage we are running without compression which is frustrating for both us from a cost perspective and for our clients who have to consume more data.

OpenSearch capacity

We've seen an increase in usage in OpenSearch CPU usage. I haven't been able to determine the extra cause of this increase - it could be extra usage, more amateur usage, or querying over more data (eg we aren't cleaning stuff up properly).
The last few days / weeks OpenSearch often hit max CPU and delayed predictions and caused other data features to fail.
What's worse is when WebSockets crashed it often causes additional CPU load on OpenSearch as clients failed back to API requests.
We've made some efforts to clean up some older data - however more research is required in this area.
Predictor issues
At some point we hit some weird limitation with the predictor where it would just go slow. I don't think we've truely worked out exactly why this has started happening but we've worked around it by improving the scaling system of the predictor to handle the load and reduce the overall response time. This system is complex are very hard to troubleshoot. We even went as far as instrumenting the server in New Relic however without past data it's hard to work out if something has changed or if we hit a performance limit.

Increased load

In the last few days of news cycles have made balloon tracking interesting to more and more people. As such we've seen over a doubling of usage of our tracking websites. I was hoping this would come and go fairly quickly however it seems this extended usage (and possibly more) is likely to stick around for longer.
We've added 3 additional websocket servers and doubled the size of our OpenSearch cluster to handle the load.
I wanted to quickly mention what happens to SondeHub during high load:
- Our WebSocket servers have a lot of burst capacity - so can often ride increases in load (see above screenshot) provided it isn't sustained for multiple days
- If OpenSearch is overloaded cached versions of results are served up where possible - this is usually enough to get the tracker to connect to WebSockets for live data. Even if OpenSearch is completely offline live data through WebSockets should work.
- Our ingestion pipeline is very robust. It's unlikely that we will drop uploaded data even with WebSockets or OpenSearch are entirely offline. It just might take awhile before data will show up on the tracker or in databases.
Future
During all this troubleshooting, debugging and increasing of resources - many changes have occurred without being committed into our infrastructure as code repo. Once things have calmed down this will be first task to fix up.
Me
During all of this I've been trying to take care of myself, but it's been fairly hard. At the moment I'll just be focusing on maintaining system uptime and availability. It may be awhile until new features are added to our APIs and backend systems. Feel free to keep on adding issues to the sondehub-infra GitHub repo but keep in mind it may be awhile before I can get to them.
That's it for now, happy balloon flying and hunting.
~ Michaela.
2023-02-15 08:49:09 +0000 UTC
View Post
Hi all,
We are currently looking into options for alternative map tile servers, however in order to do this we need to gain an understanding of how many tiles we are currently loading each month. To obtain this data we'll be temporarily capturing some very limited analytics.
Data we will be capturing:
- Number of tiles loaded for each map layer + random ID for each browser session
Data we will NOT be capturing:
- Which specific tiles or locations are being loaded
- IP addresses, callsigns, names, cookies
Once we have a clear understand of map tile usage we'll be disabling the analytics.
Please contact us if you have any concerns.
2023-01-17 05:42:17 +0000 UTC
View Post
I am very happy to announce that we have a new sponsor and partnership for 2023, GRAW Radiosondes. You may have even had the chance to recover one of their DFM series of radiosondes. Their generous support allows us to keep SondeHub free to use at the service level our users have come to expect.
We are looking forward to working and collaborating with GRAW Radiosondes over the next year as there are some exciting opportunities for us to help each other.
You can find out more about GRAW Radiosondes on their website https://www.graw.de/
2023-01-01 01:00:01 +0000 UTC
View Post
Logging reduction
- Remove MQTT logs
- Only log exceptions for ingestion
- Moved monitoring dashboard to Grafana

One thing that's always bugged me is how much we spend on logging useless info and the cost to have our pretty status monitoring dashboard. Fixing the first is a tricky problem as by default Lambda functions log their start and stop execution details - and the only way to turn this off is to turn off all logging.
To work around this we have to create our own custom logger that handles just exceptions. That's now been implemented. We also turned off much of the SNS to MQTT logging to CloudWatch as it was mostly noise. We can turn them back on if needed. That has reduced the PutLog costs (or USE1-DataProcessing-Bytes).
The CloudWatch dashboard was migrated to Grafana which we already had setup for querying radiosonde and amateur data.
It's not a lot in the grand scheme of our bill but its wastage I'd prefer to avoid.
OpenSearch Improvements
- Disk type change GP3
- Upgrade version
- Disk space reduction
- Less hot data
Mostly just maintenance tasks of ensuring our DB is the latest version and not falling behind. This also requires updating some of our API requests to match new requirements.
The disk type was switched over to GP3 which provides some better performance and more fined controls.
To save on disk space, CPU and memory utilisation we've also reduced the amount of hot data we keep in the OpenSearch database. The idea here is that we don't need to increase the size of the DB if the amount of "hot data" is kept low. All the historic data is still retained in our S3 bucket though.
Minor improvements
- Updated sonde types lists
- Backend multi sonde search (once frontend changes are implemented we'll be able to filter on multiple amateur callsigns)
- Various bug fixes and tweaks (some related to Habhub shutdown)
Future
At the moment we keep every single prediction ever run. These are slowly growing in size. We are part way through developing software to archive just the oldest entry (closest to the ground) and discard the rest to save space.
2022-12-22 10:34:45 +0000 UTC
View Post
Listener websockets
A combined effort between Mark and I has moved listener (station) updates to via websockets now! This is a huge improvement in terms of cost and performance. When a chase car updates its position it should be reflected in the web tracker within a couple of seconds.
Request counts
While we can handle a large number of requests we still get charged per request. It doesn't seem malicious and is likely fixed in our latest tracker releases, it seems two users have been making millions of requests a day. We've implemented a WAF to block these requests however that has a cost associated with it and we'd prefer to run without it.

MQTT capacity
It was discovered from user reports that we ran out of MQTT server capacity. During very peak times our servers couldn't keep up and weren't serving traffic to clients. We've added some alarms to alert when this happens again. We've doubled the number of servers that we have to handle requests. It's lovely that we are getting more sondehub users but we'll need more of these users to become Patreon members to keep up with demand.

Tracker javascript optimisations
During debugging the MQTT issues we thought it might have been related to clients browsers CPU usage. As such we spent a huge amount of time optimising the frontend it. While this didn't resolve the root issue the performance impacts do make the site more accessible on slower devices. There's probably about a 50% improvement in CPU time used for the site now.
Before:

After:

APRS Gateway
APRS gateway stopped receiving APRS-IS messages for the last day or so. It's been known on occasion for APRS-IS servers to just stop sending messages. We've setup some monitoring + auto restart for when this happens.

The gateway had +6 months of no issues prior to this. We treat APRS gateway as best effort, but regardless hopefully these changes make it a little more reliable. Sorry if you had an APRS flight during this time.
Finally...
I've probably missed many other little things that we've been working on - the project has a lot of moving parts. I'd like to thank our patreons for their support, everyone who logged details issues with us and our dev team.
2022-10-17 02:44:04 +0000 UTC
View Post
It's been a little while since I've last posted, mostly because I've been busy, but that doesn't mean progress has stopped on SondeHub. Most of the teams effort has been in supporting the retirement of Habitat and Habhub.
This has spawned a bunch of little jobs and projects such as :
We've also been planning performance improvements in SondeHub Amateur, especially around chase cars.
There's certainly been an increase in load on SondeHub Amateur and as such we are still playing catch up in this space.
2022-09-16 23:37:32 +0000 UTC
View Post
Before I kick off, I just wanted to mention that updates on the Patreon are probably going to be slow over the next months as I'll be travelling, but thats not to say progress on SondeHub will slow down. Mark and Luke are always improving the platform.
Now onto Grafana. We've had a public OpenSearch cluster for sometime now, and while it does allow users access to query the data and make visualisations, accessibility has always been an issue. It requires logging in and finding the data that you are looking for. Due to AWS limitations there's no way of embedding the data or easily linking to other users. We've been constantly updating our OpenSearch version due to promises that some of these issues are fixed but at the end of the day it's still not as accessible as we'd like.
This is where Grafana fits in. It's an analytics platform that sits front of existing databases (in this case our OpenSearch cluster). It's very configurable and this allows us the ability to provide anonymous access. No logins required for viewing.

The data is much the same as what we have in OpenSearch but we have some more flexibility in how we display it. We can provide a payload_callsign picker that allows anyone to see data about any specific payload.
At the moment we only have dashboards for SondeHub amateur but if there is interest in specific data for regular SondeHub then we can certainly add some. We can also create dshboards specific to certain flights. Eg we might create a HORUS dashboard.
Here's a link to the dashboard above : https://grafana.v2.sondehub.org/d/HJgOZLq7k/basic?orgId=1&from=1655607254426&to=1655626915820&var-Payload=ITSWINDY
Feel to have a browse around and provide any feedback on dashboards you'd like to see.
2022-06-29 01:13:00 +0000 UTC
View Post

Eagle eyed users of SondeHub may of noticed some new logos on our loading screen from ARDC, AREG and of course Patreon. ARDC and AREG have teamed up to provide financial support for SondeHub. Between ARDC+AREG and our Patreon supporters we'll be able to ensure SondeHub remains operational for the at least the next year - and hopefully more!
We are very grateful for their support and this funding allows us to focus on adding new features to the platform (eg, we likely wouldn't have been able to start working on the Amateur tracker without this).
Like wise we are very grateful for your support as well! Without Patreon supporters SondeHub would be a completely different and limited experience.
Other bits of news / additions
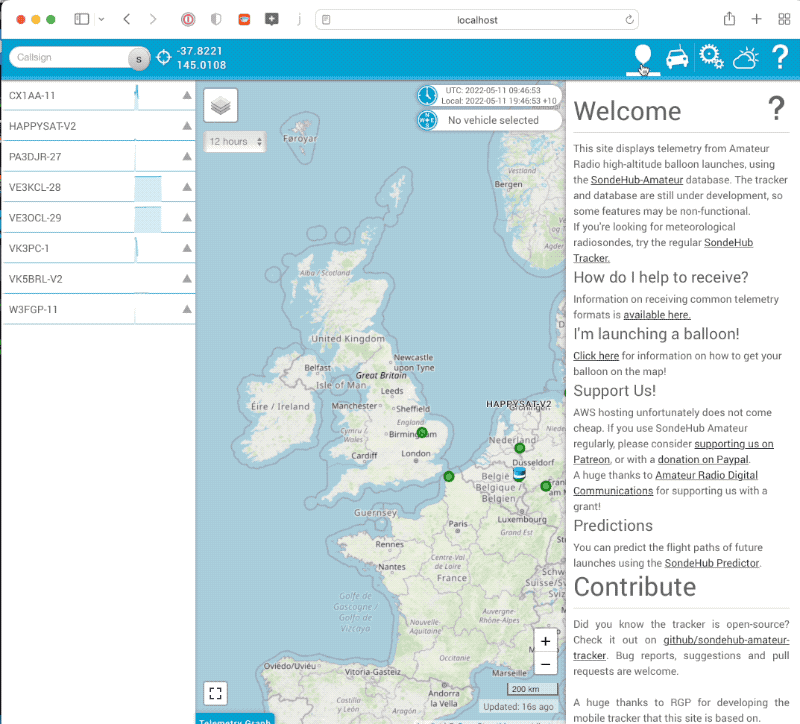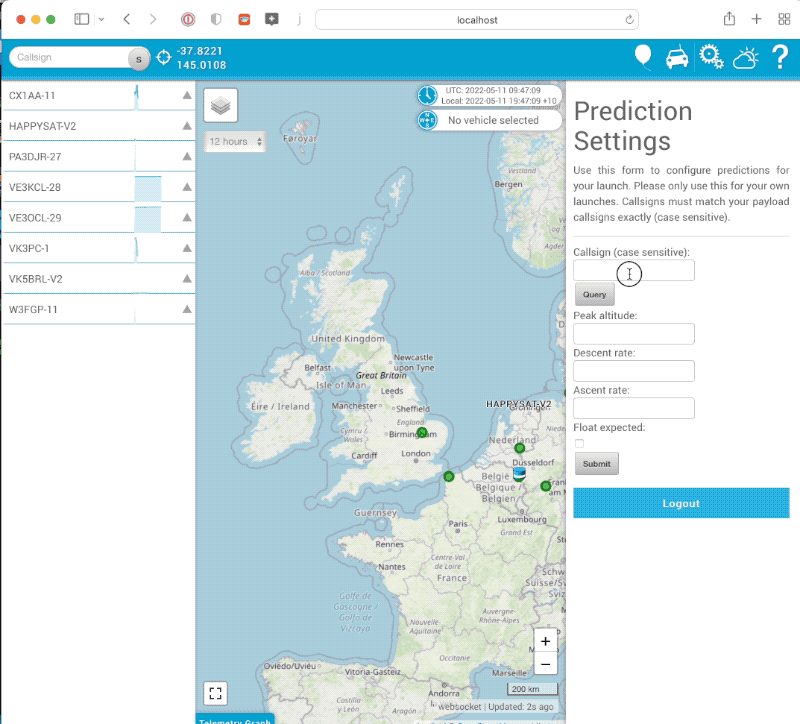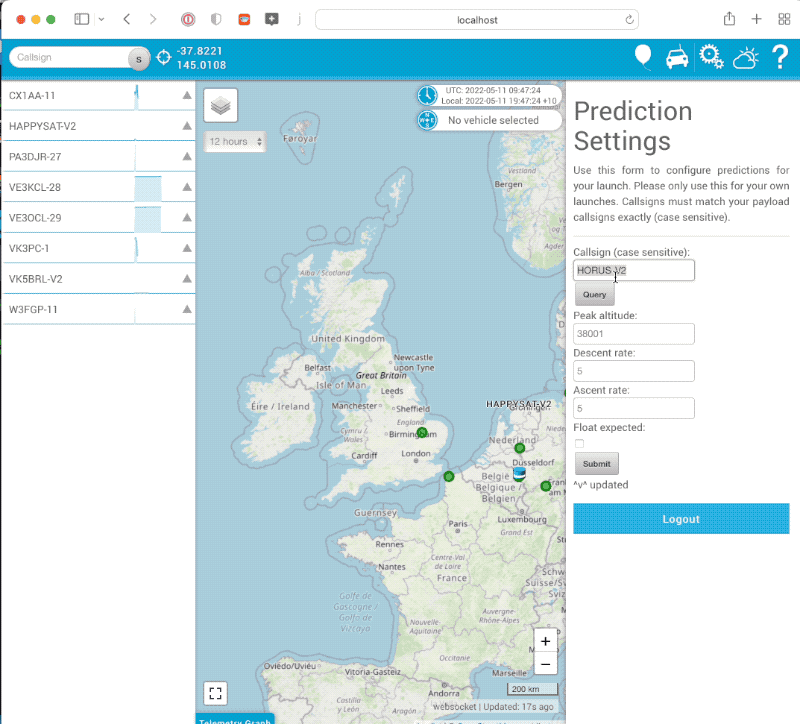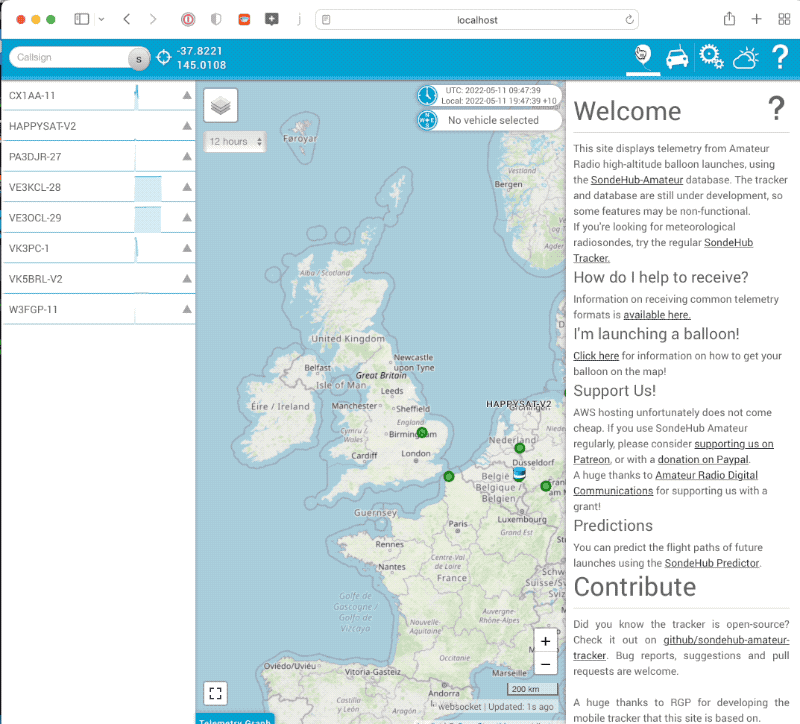
For Amateur SondeHub we want to allow users launching balloons to be able to change the prediction parameters for their launches. For this feature we wanted to add the ability for authentication and in the future authorisation. Doing so required building a login flow for the tracker and it seems to be working quite well. A few prediction settings have been reconfigured using the flow now and seems to work ok (after some of the early bugs were fixed)!
The authentication system also opens up new possibilities for having registered stations and API key generation. This is something we haven't needed yet, but something we'd like to explore in the future.
Mark has also started working on extending pysondehub to support uploading of telemetry. This will become our reference client for uploading data to SondeHub. Look out for updates in this space.
2022-05-21 23:20:21 +0000 UTC
View Post
For awhile I've mentioned that we've added endpoints in our API for tracking of amateur radio balloon launches, along with an APRS ingestion pipeline. Well we now have a tracker up!

The tracker is available at https://amateur.sondehub.org/ and provides many of the features of the typical SondeHub tracker.
Many thanks to Luke and Mark for the hard work getting this up and running.
Please note that this is very much in beta, and we are still adding, improving and testing features. Things may break from time to time. Our next focus is improving the predictions of amateur payloads and providing a location to upload expected balloon parameter.
2022-04-22 22:04:29 +0000 UTC
View Post
We recently had a DB outage and I wanted to explain what went wrong.
First some background. On Friday I upgrade our Elastic Search 7.9 cluster to OpenSearch 1.2 - this went well (however we are still monitoring performance of this change). This change was rolled out by myself manually. This was done to ensure a smooth deployment of the DB.
Today during a deployment of some new amateur features to SondeHub (there will be some future posts about these) a terraform apply was executed. Terraform is the tool we use to manage our infrastructure configuration as code. This change included updates to many of our resources. Unfortunately during this apply I didn't notice an update to the OpenSearch cluster. As the cluster had been manually updated on Friday and the respective version wasn't updated in terraform configuration, terraform considered the desired outcome was to downgrade the cluster back to ElasticSearch. As there is no way to perform a downgrade terraform replaces the resources (deleting the cluster and creating a new one).
This was noticed very quickly during the apply - unfortunately there is no way to cancel a deletion. Snapshots are taken every hour and after contacting AWS they were able to restore the DB. This entire process took just under 4 hours.
During this time SondeHub continued to operate however in a very degraded state. The tracker showed cached locations of all sondes, and live updates were still processing. Behind the scenes new data was being queues in SQS ready for the DB to return.
In the end no data was lost and the queues were processed once the database was restored. I'm terribly sorry for any issues this caused. I've already implemented terraform lifecycle policy on the OpenSearch cluster to prevent this specific issue from reoccurring.
So a quick recap:
- API / DB was down for ~4 hours
- No data lost
- Site still worked in a degraded form
Things we've already improved:
- Added a lifecycle policy to the DB to prevent destroys
Things we can do better:
- We relied on AWS for the snapshot restore - we could take our own snapshots however this may be too expensive / complex
- I can check terraform plans in more detail
Unfortunately in the end we have to accept a certain amount of risk to keep operating costs low but we try our hardest to reduce these.
Feel free to ask any questions in the comments.
~ Michaela
2022-04-09 09:10:51 +0000 UTC
View Post
We were alerted that predictions were old / delayed. Upon investigating it appears that over time the function that processes our predictions was taking longer and longer to process predictions. It appears that in some edge cases some radiosondes were causing Tawhiri (the software we use for predictions) was taking over 30 seconds to process.

When we had several of these events occur at once it pushed the latency of that function longer than its time out of 5 minutes and predictions would never finish. The cause of this still isn't fully understood. Once that issue was identified I looked into running the predictions in parallel. This way if a handful of sondes took longer than 30 seconds, the others will work in parallel and eventually finished.

This change was successful however this caused issues with Tawhiri that we didn't anticipate. For some reason running many requests to Tawhiri started to cause issues. We've never seen this before - even when benchmarking Tawhiri.
After a few requests Tawhiri would stop providing good results - as if the dataset was corrupted.

A working query against the same dataset would return a "Prediction did not complete" error message a few minutes later.

It seems like some of the queries we were running were causing worker timeouts and the new workers were unable to see the dataset.
I tired:
- Restarting the service to make sure the dataset was correct
- Not running predictions that are less than 0.8m/s vh
- Reducing how many parallel requests are made
In the end what seems to have resolved the issue is switching the worker type for gnuicorn from sync to gthread - having 1 worker and 20 threads.
I'm not sure exactly why this has helped but we are no longer seeing worker timeouts (good since there is only one worker) and performance appears to excellent. Regardless the error rate dropped away and we started getting good predictions again.

Future Improvements
One of my frustrations with this incident is that we weren't aware of the issue until people told us that predictions weren't working. There are two reasons for this:
- poor alerting on the predictions service
- Tawhiri lacking health check
There's currently no alerting when the prediction service takes too long or the error rate is high. I plan on fixing this.
Tawhiri in its current configuration is only tested to see if its web service is running - not if its providing a good prediction. I intend to address this by having it test running an actual prediction. This is non trivial as I need to make the health check take into account the current date and time but shouldn't be too hard to implement.
2022-03-18 08:26:27 +0000 UTC
View Post
We've been progressing a little bit on amateur balloon tracking and recently AREG launched a balloon "UPANDUP" which was tracked by several stations running the latest version of horus-gui which now contains support for SondeHub as an upload location.
As an experiment I decided to play around with the ElasticSearch dashboards that we could use for analysing these sorts of flights.

It was extremely fun to play around with the data and I can see this being useful for amateur radio balloon launches in the future. We may we port this dashboard over to normal radiosondes. At the moment its still very much a prototype but I look forward to watching it grow.
2022-02-16 00:42:38 +0000 UTC
View Post
As SondeHub grows in the number of stations and the number of website users our data transfer costs increase. When there was only a handful for stations using SondeHub this wasn't a big deal but now that SondeHub but now that SondeHub is nearing 800 stations the data transfer fees are starting to add up. In the last month alone we've picked up an extra 100 stations! Added to this when we migrated from habhub it was done in a way to minimize the time to switch over. APIs were rushed into production and not much thought went into to optimisation. Last month data transfer costs became our number one expense. Because of this I spent some time over the last few weeks to optimise our platform to reduce this cost, and I'll run through some of the savings we've made.
SNS message compression
To ensure reliability and performance within SondeHub we heavily rely on Simple Notification Service (SNS). SNS is a message distribution system. When we receive a batch of frames on the API we turn this in an SNS message. SNS then passes this on to Simple Queue Service (SQS) for processing into ElasticSearch, along with a Lambda function for processing onto websockets / MQTT.
A typical SNS message for SondeHub is a JSON array of payload data. In my test case, about 7879 bytes. (for the purposes of testing I've actually used payloads from several different receivers to make the task the worst case scenario - much higher entropy)
SNS per message cost is free for SQS and Lambda (we get charged on the SQS and Lambda side), however you are still charged for data transfer - $0.09 per GB.
To reduce this overall cost we can compress this down. Using GZIP this gives us 1401 bytes. There's a problem here though. SNS and SQS require strings, not binary data. So we then have to base64 the data. After base64ing the data we get back to 1869 bytes. This gives us roughly a 4.2x compression ratio.
The code to do this is actually quite simple:
<code><code>
# compress compressed = BytesIO()
with gzip.GzipFile(fileobj=compressed, mode='w') as f:
f.write(json.dumps(payload).encode('utf-8'))
payload = base64.b64encode(compressed.getvalue()).decode("utf-8")
#decompress decoded = json.loads(zlib.decompress(base64.b64decode(sns_message["Message"]), 16 + zlib.MAX_WBITS))</code></code></code>
And in practice we can see the decrease in our overall SNS spend

AZ Traffic
Inside AWS you can choose where your data and compute are stored. There's two main concepts, regions and availability zones. An availability zone basically one or more datacenters. Availability zones don't share any resources with each other. Regions contain multiple availability zones. Availability zones within the same region are interconnected allowing for high speed traffic.
Moving data around costs depends on where your moving it. The basic version is:
- Traffic inside an availability zone is free
- Traffic between availability zones is cheap
- Traffic between regions is a little more expensive
- Traffic out to the internet is very expensive
SondeHub is hosted in a single region however we had some interesting traffic flows. Most of our Lambda functions don't use a VPC to allow them to have quick startup times. The problem with this approach is that when we place messages on the websockets we are being charged for traffic to a load balancer.
The Lambda function that posts to the websockets endpoint was updated to use the internal IP addresses and limited to only be a single availability zone. This required a little bit of extra logic to detect which IP address was active internally but the end result is we are no longer charged for this traffic.
Our websocket servers were also modified to be single AZ to reduce traffic costs.

ElasticSearch compression
Another big saving was ElasticSearch compression. For a long while we have been compressing our requests/queries to ElasticSearch. However we never sent the required headers to get a compressed result. What this meant is that is that all our responses (which are sometimes containing thousands of documents) were completely uncompressed JSON.
Adding compression to the responses was pretty straight forward:
<code><code> headers = {"Host": ES_HOST, "Content-Type": "application/json",
"Content-Encoding": "gzip", 'Accept-Encoding': 'gzip'}
...
if (
'Content-Encoding' in r.headers
and r.headers['Content-Encoding'] == 'gzip'
):
return json.loads(zlib.decompress(r.content, 16 + zlib.MAX_WBITS))</code></code></code>
This provides a significant cost saving on more data costs.

Lighsail for data out
The final data saving was really about picking the right services for the job. Inside Fargate (where we host websockets) we are charged $92 per TB of data transfer out to the internet. However if we host our application inside Lightsail, we can get a 1core / 512MB instance with 1TB of traffic (in/out) for $3.50/month. Significantly cheaper and we get compute as well! Lightsail does have some limitations such as no autoscaling.
We switched to 3x the $5/month Lightsail instances as they provide 2TB a month each - this is well over our typical usage so shouldn't require autoscaling to cope with most of the traffic spikes we see while still providing a significant reduction is overall data transfer out costs.
As these are running inside Amazon it was also possible to configure them to be Elastic Container Service hosts which made migrating over easy as we just provisioned our websocket container tasks to the new hosts.
The only tricky part of this is that we are forced to use the Lightsail load balancer and rely of health checks to add and remove the instances from the load balancer - however this is fine for us.

That's all I have for today. Thanks to all our patreons for your support!
~ Michaela.
2022-02-16 00:20:33 +0000 UTC
View Post
XDATA Instrument Decoding

The radiosondes that we detect will sometimes include secondary instruments such as Ozone sensors which transmit their information via the XDATA protocol in telemetry. We can receive the raw transmitted XDATA values for RS41 and RS92 sondes with radiosonde_auto_rx with iMet-1/4 also coming soon. The DFM and M10/20 sondes also support XDATA but we cannot currently decode these values from telemetry due to a lack of sample recordings (if you are within range of a location launching either of these sondes with XDATA instruments please get in touch).
We previously didn’t process these raw values which limited their usefulness, so recently initial support for decoding has been added to the SondeHub tracker. There are approximately 20 different XDATA instruments flown but the Viasala OIF411 Ozone interface board accounts for the large majority of samples in the SondeHub database so that was the initial focus.
Mark Jessop created an initial Javascript function that could decode raw OIF411 XDATA frames and return the pump temperature, along with power measurements for various instruments. He also added support for determining the approximate 03 partial pressure using these values along with the sonde detected pressure and placeholder calibration values resulting in an output that is within +/- 1 mPa of the 'truth' data.
Luke Prior worked on integrating this script into the tracker and also created four more decoders for other popular XDATA instruments and support for detecting the type for others. These included the Compact Optical Backscatter Aerosol Detector and Peltier Cooled Frost point Hygrometer from ETH Zurich, the Fluorescent Lyman-Alpha Stratospheric Hygrometer from Central Aerological Observatory, and the Peltier-Based Chilled-Mirror Hygrometer from Meisei.

The XDATA formats for all these instruments have been documented on the sondehub-infra wiki here: https://github.com/projecthorus/sondehub-infra/wiki/XDATA-Decoding and we would strongly encourage anyone with further information not listed to get in touch. We hope to add support for the remaining instruments which are regularly flown such as the EnSci CFH, and NOAA FPH provided we can find the required documentation.
The decoding is currently done entirely within the SondeHub tracker with only the raw frame data being stored in the database. We plan to eventually migrate this to our ingestion pipeline to support keeping track of calibration values and allowing other programs to easily access the information.
Radiosondy.info Recovery Ingestion
We have been working with Michał Lewiński SQ6KXY the creator of Radiosondy.info to facilitate the sharing of recovery information between the two sites. You may have noticed this already on the tracker and SondeHub recoveries should appear on Radiosondy.info soon.
We faced some difficulties in matching the recoveries from Radiosondy.info to our SondeHub records as only the RS41, RS92, and DFM sondes use the same serial on both sites. The solution we are using for all other sondes is using the launch time, position, sonde type, and frequency to check for matching values in the SondeHub database.
This setup works sufficiently and we are able to process most of the recoveries from Radiosondy.info. The addition of this recovery support will improve the historical launches feature and allow users to submit a recovery on a single site and have it appear on both.
2022-01-29 06:53:19 +0000 UTC
View Post
The SondeHub tracker has been updated this month gaining two new major features, viewing historical launch site data, and generating Skew-T plots. The historical launch site data allows you to plot the landing positions for all sondes assigned to a specific launch site. The launch site modal has been expanded to allow for a year and month selection of data to display.

The historical data is than loading from the AWS S3 bucket and we check if there is any recovery information for the sondes before we plot the downloaded data on the map. The last known positions are marked with a circle marker where the outer ring colour indicates the altitude with 'cooler' colours representing altitudes close to the ground, and 'warmer' colours representing altitudes higher in the air. The contents of the circle will be white if no recovery information was found and grey if information was found.
The entire flight path for these historical sondes can be downloaded by opening the modal by clicking on the marker and selecting the flight path option. This modal will also show information about the sonde download from S3 including the receiver of the last frame and any recovery information.
The other new feature introduced to the tracker is the ability to generate a Skew-T plot for any sonde with the required weather information. The Skew-T chart can be generated for any loaded sonde by selecting the Skew-T button from the sidebar.

The complete data for the sonde will be downloaded from AWS which may take 20s+ depending on the amount of data available. The downloaded sonde information will be processed into a format that the Skew-T library can process.
~ Luke
You can check out these features on the testing version of the site at https://testing.v2.sondehub.org/ . Mark (VK5QI) has put together a user guide here : https://github.com/projecthorus/sondehub-tracker/wiki/SondeHub-Tracker-User-Guide
2021-12-26 02:36:46 +0000 UTC
View Post
Predictor Updates
We've been having issues with our home run predictor. When a prediction would run the server would lock and several requests would take a long time too come back. Previously we ran the predictor using a wind model that was shared via EFS (basically AWS managed NFS host). The predictor itself would memory map that file and read through it to provide a prediction.
I suspect the issue is with the way NFS and the Linux kernel locks the file during memory mapped reads. To solve this I moved the files onto the ECS task (docker container group) and we mostly got rid of the EFS component. This led to the next problem.
On startup the ECS task would download the latest model the run the predictor - while the predictor was running the downloader would constantly run and pull in updates. Over time we noticed the predictor would stop running correctly, and appeared to be due to wind model data corruption. I suspect this is due to how the wind model is being updated and some caching going on with the memory mapped file.
To resolve this we now subscribe to the SNS feed of file uploads from NOAA. When we detect the last file from the wind model being uploaded we trigger a new deployment. This new deployment will download the latest wind model. This system seems fairly efficient and means we typically see the new model being utilised in under 10 minutes from upload.

Here we are showing the typical switch over between the old wind model and the new wind model. It's performed using an ECS deployment.
OpenSearch / ElasticSearch


A couple of months ago we switched from ElasticSeach to OpenSearch and it was very clear from the switch that there was a significant and unexpected change in performance. We've been working with Amazon closely to try to and resolve this.

To help debug the issue we've actually setup both ElasticSearch and OpenSearch at the same time. Both are ingesting the same data, and every search query thats run is replicated on both servers. This took a significant amount of work but should help in debugging the issue.
Hopefully we can get to the bottom of this issue, otherwise we might be stuck on an older version of ElasticSearch for longer than we want.
That's all I have for the moment. Hit me up with any questions you might have about the platform :)
2021-12-06 00:30:42 +0000 UTC
View Post
I've had this week off from work so I've had a little bit of time to work on various parts of SondeHub. Most of the work I'm doing has been around cleaning up our terraform configuration. Terraform is the tool we use to manage everything that's deployed in AWS.
Our infrastructure has lots of moving parts, gateways, functions, CDNs, servers and everything in between. Each little aspect of our environment has many many many configuration options, like Python version, function name, memory usage, API path ect...

While I can happily click through the AWS console and build out a bunch of resources it hides how I configured it and makes it harder for anyone else to make changes. By using Terraform we can write all the configuration in a single spot, and start mapping the dependencies between the services we use.

Although not very practical here's a map of some of the SondeHub infrastructure as viewed by Terraform. It's a good example of how GUIs sometimes hide the complexity of the systems we are building.
So what's next in this space? There's a few resources that we don't have setup in terraform yet so I'll be working to add these in, followed by developing a build and deploy pipeline for this configuration. This will make it a lot easier for our team to make and test changes. The ideal place we want to get to is being able to deploy out your own SondeHub infrastructure for development.
Other updates
We are also working on a few other bugs and quirks such as the launch site predictions, including transmitted frequency (eg the frequency that the sonde is reporting vs the user) and some time formatting issues.
Another focus we are planning is handling different time scales. The observant SondeHub users will note that some radiosonde data seems to be from the future, by about 18 seconds. Currently SondeHub stores time based on the reported time from the radiosonde, however this typically doesn't include any leapseconds - unlike UTC. We'll be exploring the best approach to this soon and is quite a complex problem.
Once again, many thanks to Mark and Luke for their amazing work on SondeHub!
~ Michaela
2021-10-28 22:57:44 +0000 UTC
View Post
Regular users of the SondeHub tracker will be familiar with the live flight-path predictions run for all radiosondes showing up on the map. These predictions are run using the 'Tawhiri' prediction software (developed by Cambridge University Space-Flight - CUSF), which itself uses the NOAA's Global Forecast System weather model. We run our own instance of Tawhiri to avoid overloading the CUSF instance, pulling wind model data from the AWS mirror of GFS.
Along with the live predictions, we added the ability for users to run flight-path predictions for known launch sites. This can be accessed by turning on 'Show Launch Sites' in the Settings tab, then clicking on a launch site (grey circle). We have been able to obtain schedule data for many launch sites through the World Meteorological Organisation, though some are still unknown. For many launch sites we have been able to analyse the huge amount of data in the SondeHub DB and determine information on the average flight profile parameters (ascent rate, burst altitude, descent rate), increasing the accuracy of these forward-looking predictions.

Recently we added functionality to our fork of Tawhiri to allow 'reverse' predictions. These are performed by stepping backwards in time from a provided time and position, allowing an estimation of where a radiosonde was launched from. Reverse predictions are run automatically on the first data points received for each radiosonde serial, stored into the SondeHub database, and shown on the map as a partially transparent path preceding the normal flight path.

This helps us in a few ways:
- We can estimate which launch site a particular radiosonde originated from, and use known flight profile information from that launch site to improve the accuracy of the live predictions.
- We can maintain a record of what serial numbers were launched from each launch site, enabling easier lookup of historical flight data for a particular site.
- We can discover previously unknown launch sites, including temporary launch locations such as ships and fire-fighting areas.
Access to the reverse predictor is also available as a flight profile option at https://predict.sondehub.org/
~ Mark VK5QI
2021-10-10 03:37:29 +0000 UTC
View Post
A feature we've been meaning to get to is showing predictions for longer. What do I mean by this?
Previously predictions only used the last 5 minutes worth of data to generate a prediction, however this was based on current time. So if the radiosonde had not been received in 5 minutes then the prediction wouldn't run. Some of our users enjoy trying to find radiosondes well after they've landed and after the radio transmitter had stopped so its necessary to have a good idea of where the radiosonde was likely to land.
As of this afternoon predictions are now saved in our ElasticSearch cluster and if all goes well you should be able to saved predictions with each radiosonde flight.

For example this radiosonde landed roughly 30 minutes ago and we can still its prediction up on the map.
Because we save all the data now this allows us to visualise the predictor. This could be useful to detecting issues with our prediction models or software. Here's the same radiosonde above but visualising the predictions over time.



I'm sure a lot of you are going to have fun this new data and enjoy trying to recover old radiosondes. Just remember that it only applies to radiosondes launched to today onwards. You should also see more frequent predictions compared to the old method.
Implementation details
The implementation of this is actually fairly simple. Basically the old predictor logic has been moved to a Lambda function that's run every minute. This queries ElasticSearch like it did before to find radiosondes in the last 5 minutes and calculate their ascent/descent data. It then queries our Tāwhirimātea (CUSF flight predictor) instance and then save the results back to ElasticSearch
The API endpoint was simply updated to query ElasticSearch for the results rather than Tāwhirimātea.
That's all I have for today. I've been finding it hard to get time to focus on this sort of work so it's pretty rad to finally get this fixed up. It's been bugging me for several months now!
Stay safe, and all the best
~ Michaela
2021-09-13 07:30:59 +0000 UTC
View Post